Insertion sort belongs to the O(n2) sorting algorithms. Unlike many sorting algorithms with quadratic complexity, it is actually applied in practice for sorting small arrays of data. For instance, it is used to improve quicksort routine. Some sources notice, that people use same algorithm ordering items, for example, hand of cards.
Algorithm
Insertion sort algorithm somewhat resembles selection sort. Array is imaginary divided into two parts - sorted one and unsorted one. At the beginning, sorted part contains first element of the array and unsorted one contains the rest. At every step, algorithm takes first element in the unsorted part and inserts it to the right place of the sorted one. When unsorted part becomes empty, algorithm stops.This will keep the left side of the array sorted until the whole array is sorted.
Example. Sort {7, -5, 2, 16, 4} using insertion sort.

Complexity analysis
Insertion sort's overall complexity is O(n2) on average, regardless of the method of insertion. On the almost sorted arrays insertion sort shows better performance, up to O(n) in case of applying insertion sort to a sorted array. Number of writes is O(n2) on average, but number of comparisons may vary depending on the insertion algorithm. It is O(n2) when shifting or swapping methods are used and O(n log n) for binary insertion sort.
From the point of view of practical application, an average complexity of the insertion sort is not so important. As it was mentioned above, insertion sort is applied to quite small data sets (from 8 to 12 elements). Therefore, first of all, a "practical performance" should be considered. In practice insertion sort outperforms most of the quadratic sorting algorithms, like selection sort or bubble sort.
"SELECTION SORTING"
Selection sort is one of the O(n2) sorting algorithms, which makes it quite inefficient for sorting large data volumes. Selection sort is notable for its programming simplicity and it can over perform other sorts in certain situations (see complexity analysis for more details).
Algorithm
The idea of algorithm is quite simple. Array is imaginary divided into two parts - sorted one and unsorted one. At the beginning, sorted part is empty, while unsorted one contains whole array. At every step, algorithm finds minimal element in the unsorted part and adds it to the end of the sorted one. When unsorted part becomes empty, algorithm stops.
When algorithm sorts an array, it swaps first element of unsorted part with minimal element and then it is included to the sorted part. This implementation of selection sort in not stable. In case of linked list is sorted, and, instead of swaps, minimal element is linked to the unsorted part, selection sort is stable.
Let us see an example of sorting an array to make the idea of selection sort clearer.
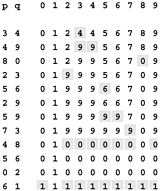
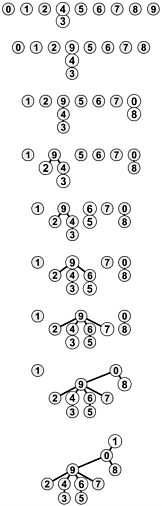
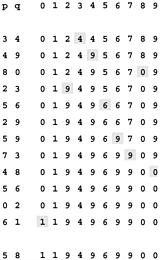
Example. Sort {5, 1, 12, -5, 16, 2, 12, 14} using selection sort.

Complexity analysis
Selection sort stops, when unsorted part becomes empty. As we know, on every step number of unsorted elements decreased by one. Therefore, selection sort makes n steps (n is number of elements in array) of outer loop, before stop. Every step of outer loop requires finding minimum in unsorted part. Summing up, n + (n - 1) + (n - 2) + ... + 1, results in O(n2) number of comparisons. Number of swaps may vary from zero (in case of sorted array) to n - 1 (in case array was sorted in reversed order), which results in O(n) number of swaps. Overall algorithm complexity is O(n2).
Fact, that selection sort requires n - 1 number of swaps at most, makes it very efficient in situations, when write operation is significantly more expensive, than read operation.
"BUBBLE SORTING"
Bubble sort is a simple and well-known sorting algorithm. It is used in practice once in a blue moon and its main application is to make an introduction to the sorting algorithms. It belongs to O(n2) sorting algorithms, which makes it quite inefficient for sorting large data volumes.It is stable and adaptive.
Algorithm
1. Compare each pair of adjacent elements from the beginning of an array and, if they are in reversed order, swap them.
2. If at least one swap has been done, repeat step 1.
You can imagine that on every step big bubbles float to the surface and stay there. At the step, when no bubble moves, sorting stops. Let us see an example of sorting an array to make the idea of bubble sort clearer.
Example. Sort {5, 1, 12, -5, 16} using bubble sort.

Complexity analysis
Average and worst case complexity of bubble sort is O(n2). Also, it makes O(n2) swaps in the worst case. Bubble sort is adaptive. It means that for almost sorted array it gives O(n) estimation. Avoid implementations, which don't check if the array is already sorted on every step (any swaps made). This check is necessary, in order to preserve adaptive property.
"SHELL SORTING"
Shell sort is the most efficient of the O(n2) class of sorting algorithms. It is also the most complex of the O(n2) algorithms. This algorithm is similar to bubble sort in the sense that it also moves elements by exchanges.
Shell sort begins by comparing elements that are at distance d. With this, the elements that are quite away from their place will move more rapidly than the simple bubble sort.
In each pass, the value of d is reduced to half.
In each pass, each element is compared with the element that is located d indexes away from it, and an exchange is made if required. The next iteration starts with a new value of d.
The algorithm terminates when d=1.



Analysis of Shell Sort
1. It is difficult to predict the complexity of Shell sort, as it is very difficult to show the effect of one pass on another pass.
2. One thing is very clear that if the new distance d is computed using the above formula, then the number of passes will approximately be log2d since d=1 will complete the sort.
3. Empirical studies have shown that the worst case complexity of Shell sort is O(n2).
To know more about sorting algorithms just click the sites below. I've also search the animation for better understanding.
http://www.cs.oswego.edu/~mohammad/classes/csc241/samples/sort/Sort2-E.html
http://www.cs.pitt.edu/~kirk/cs1501/animations/Sort1.html
http://www.algolist.net/Algorithms/
http://www.tech-faq.com/shell-sort.html


{kind=link}